The following is a rough transcript from my presentation at HackFest 2016, on the 5th November 2016
Good Afternoon Everyone, I am so excited to be here today to talk to you about anonymity systems and how they break

My name is Sarah , I am in independent anonymity and privacy researcher/engineer. Prior to this I was a security engineer at Amazon working on preventing fraud through abuse of autonomous & machine learning systems, and way before that I was a computer scientist at GCHQ in the UK, doing stuff I can't tell you about.
All the work that I am going to show you today is published on the site mascherari.press - where I write abou anonymity and privacy issues.

So a quick overview of the agenda - I'm going to start off with a very quick introduction to hidden service operational security - I'm not going to bore you with how Tor works, the base model you need for this talk is much smaller. With that I am going to give you a quick tour through my top 5 risks to anonymous systems from some research that I conducted at the beginning of the year.
Then we going to get into the heart of the talk, and I am going to lead you through my last few months of research investigating exactly how anonymous the dark web is. And with that we are going to look at a few case studies - important to note that I while I am going to talk about deanonymziation vectors I am not going to directly reveal information which would lead to deanonymization.
Finally, I'm going to end with some thoughts on future research and talk about how we can start to fix some of the issues that I have identified.

I am going to talk to you about hidden services, in particular how to deanonymize hidden services, quickly, at scale and very cheaply. This is isn't a new crypto breakthrough and this doesn't impact the tor network or any other anonymity network. Instead, everything I am going to demonstrate today can be traced back to bad assumptions made y the operators or software designers about what kinds of information we need to protect.
The most important thing that you need to keep in mind with Hidden Services is that they only seek to hide location - that is IP address - by design. The services hide behind an anonymity network like Tor and so clients never learn the services IP addresses and the service never learns the clients IP address. Nothing about the design of hidden services prevents them from revealing information about themselves - for example, I operate a bunch of hidden services, all of them are linked back to by clearnet identity - It's really easy to find out that I run them.
This talk is going to focus on unintentional identity leaks in hidden services - from the really obvious to the horribly persistent - to the ones that are only an issue if your adversary correlates across the whole dark and clear web. But as we will see, that is really not that hard.
At the beginning of this year I conducted my first mass scan of ~8000 dark web site looking for well known, well document misconfigurations. Something to note about these kinds of scans is that they are done over multiple days and weeks as the uptime of many hidden services is volatile. After extensive manual analysis I came up with the following Top 5 risks to hidden services, based on the numbers and severity of issues seen in the wild.

The first one is open directories - these are very common on the clearweb too, but they can be particularly bad for hidden services. Administrators tend to like to leave things lying around in directories they think no one will look at, or they like to put information in commonly named folders like "backup" - the screenshot on the slide shows a directory listing I found on a service- each of those folders contains the hosting files for 22 hidden services - letting us make the determination that all those hidden services are hosted on the same server - these include multiple drug marketplaces and a social network - knowing that hidden services are co-hosted is very useful if you are trying to work out if those services might be related. Perhaps worse than that is the top folder which reads Backup - and contained a bunch of sql database dumps and config files for one of the sites.
I've also found large image caches, a backup of someones trello board containing their homework plans - and a bunch of zip files containing various content.

Number 4 is EXIF metadata - this is data encoded along with an image that tells you information about where it was taken, on what kind of device, or the software the image was edited on etc. EXIF images are not as big as a problem as they were a few years ago - you can still download scraps of marketplaces captured then and find images of cocaine for sale with GPS coordinates which you can pin down to a house in Boston and using streetview you can pick out the window in the background where the photo was taken.
Recently most large marketplaces now re-encode all the images that are uploaded to them, ensuring no metadata is left for analysis - however on small sites or vendor pages you can still often find images containing EXIF metadata - although GPS data is much, much rarer than it used to be. The screenshot is a collection of really off image editing software tags I pulled put of a marketplace - this could be very useful if you are trying to learn more about the person making these images,do they use Windows or Mac, are they using random software, are they using software that came bundled with their camera? etc.

Number 3 is cloned sites - During our scan we found that 29% of onion services have at least one duplicate - and by duplicate I mean the sha1 hash of the pages content is identical - which is a high bar for duplication - more recent work by myself and others shows this number is likely higher once you account for certain dynamic content on the page.
Many of these duplicates are intentional - either because a site is load balancing across multiple onion domains - or they have spammed 100 different versions of their site. However there are a significant number of these that are, so called, cloned sites - these are sites which silently proxy request from one domain to the legitimate domain and spy of the traffic in order to replace things like bitcoin addresses etc. Often the only way to detect these is to look at every image image on the site and to see if there is a watermark or similar information that matches the onion site you are visiting.

Number 2 is SSH Fingerprinting - also under here I group software banner fingerprinting - this is the idea that certain things about the software you are using are unique to you - the key one, if you are exposing an SSH server along with you site is the public key. Each server generally has a unique public key and so we can determine if two hidden services share a server if they both share an SSH fingerpint - also if you have misconfigured you server and the ports are available to the clear internet too then you are likely to be unlikely enough to end up in Shodan - and then it is a simple case of looking up your SSH public key to find you hidden servers IP address.
I have found at least 30 sites that are vulnerable to just SSH fingerprinting through Shodan. And it isn't just SSH keys, I've observed the same deanonymizations with unique combinations of server version (e.g. a particular version of php and a particular perl and a particular python etc.) those combined can get unique quickly, and Shodan is very helpful in filtering out those!

Number 1 is local host bypasses - these occur when the software you run on your hidden service gives special permission to localhost traffic - or assumes that you have done extra configuration before putting it on the internet - the major one of these is Apache mod_status. When I scanned back in April I found that 6% of the servers I scanned had an Apache localhost bypass revealing everything from IP addresses of the server, to other sites hosted on the same server, all the way up to the IP addresses of clearnet users in the cases where the clearnet and dark web sites where hosted on the same server.
These kinds of bugs can be devastating and they are really common. If you just consider Apache installs then 12% of all Apache installs have mod_status leaks - and despite publicity over the last few years that number is going up not down.
It's not just Apache, there are a bunch of software installs which don't do the necessary diligence on localhost connections - I have found open i2p console, wikis and even a few phpmyadmin instances not locked down - In one case the phpmyadmin was clearly on the data receiving end of a botnet each table entry contained a request from a clearly compromised computer. - which goes to show these things can be really bad.
So back in April after all this examinations I launched a tool called OnionScan which checked for all of these things, and many more - it's had really positive reviews from the clearnet and the darknet, I know it is being used in practice by many darknet site operators to protect their pages. I've also been able to work with universities, journalists and others sites where I have found these issues and helped them correct.

So that was April - since then I have continue to work on OnionScan and expanded it to a wider project, -these are our goals - number 1 of which is to map the dark web, to understand what people are using it for, to understand where people are using it insecurely, and to make recommendations and build software to actively counteract that. Sub goals of that are to increase the kinds of protocols we scan and the kinds of identifier correlations we uncover - since the initial release of OnionScan the community has been awesome at providing new protcols and new identifier correlations - apart from just HTTP, SSH and FTP we no have Bitcoin, VNC, XMPP, IRC and a bunch of others.
And since April I have also been busy scanning the dark web - every month I produce a report on some aspect of dark web usage , usually focused on security, opsec. And I am not going to lead you through the kinds of information you can extract from anonymity networks when you start correlating everything you scan.

This image is a graph of the dark web - it's very pretty, at least I think so, it's worth noting that this is a transitive reduction of the actual graph - it is that way because the actual graph as way too many connections to be visually useful - so keep that in mind as you look at this - where you see chains of nodes on this graph all of those nodes can be connected to each other in the original graph.
There are 4 colours of links on this graph Green, Pink, Blue and Red. Green connections are the least ominous they are simply hyperlinks between services - what you see on this graph is a lot of starburst links - these are sites that link to a lot of other sites, you also see a few small clusters where all the sites link to each other - these are particular interesting as this kind of link connectivity might mean an underling relationship, or less ominously the same ad network!
Pink links are sites that share the same FTP server, there is one hosting provider in particular that exposes an FTP server on each of the hidden services it hosts - that makes it trivial to determine if a site is hosted by that hosting provider.
Likewise the massive blue ring all around this graph are SSH servers. Freedom Hosting II is one of the largest hosting providers on the dark web, by my estimates they host between 10 and 20% of ALL stable hidden services, and I know that because every single one of their sites has an exposed SSH server meaning we can link them. These kinds of software correlations also exist for SMTP servers although they are rarer.
The freedom hosting case is particular important because they have been having hosting problems recently and completely dropped off the dark web for most of September, and only just reappeared again a couple of weeks ago - I now have a job that regularly tracks the uptime of various freedom hosting servers because when it disappears it takes a lot of varied content with it - and that's important for reasons I will come to at this end of this presentation.
Finally, it may be tricky to see but there are a few small clusters of red links on this graph - these are hosts we have been able to link together because they expose an Apache mod_status page and on that page lists all the other hidden services hosted by the same service - we have found 11 distinct clusters of services that are like this, and this tells us something interesting, especially combined with the SSH and FTP results I just mentioned...
It means that the dark web is actually, physically, much smaller than previously estimated - it looks like at least 50% of dark web sites are hosted by only 20-50 entities - whether these are dark web hosting providers, or dedicated operators, or simply 1 cartel running 5-10 different front sites. This has huge implications for estimating the amount of crime and other activities that is facilitated using anonymity system. 4 drug marketplaces might only be run by 1 group in which case is that 4 drugs sites, or 1 black market group? How we count these things has large political implications. Something I'll revisit soon.
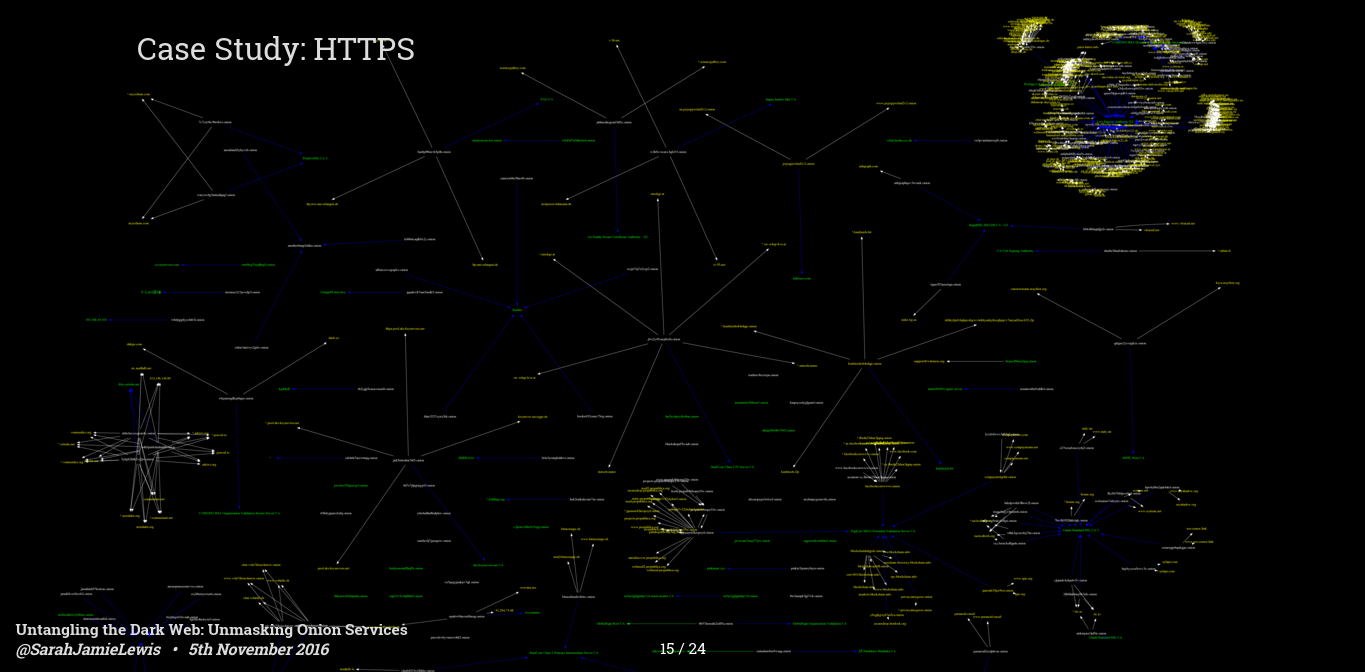
I now want to move onto HTTPS/TLS certificates. Back in July I spent some time analyzing how dark web sites were using, (and mostly abusing) HTTPS. It's worth noting here that there is very little reason, security wise, for a dark web site to opt for a HTTPS certificates - hidden services provide end to end, forward secure encryption- by laying TLS on top the only thing you are really buying is identity verification - and this is why we see only 7 sites having legitimate HTTPS certificates - these are privacy charities like Privacy International, with Facebook and Blockhain also having a legitimate HTTPS certificate.
But this map shows many more than 7 sites, and this is because there is an awful lot of HTTPS misconfiguration going on - the bright cluster in the top right are let encrypt certificates, often signed for clearnet domains and then served on dark web sites, and that is a trend that you see for the rest of these, many of these services are accidentally exposing port 443 to the dark web and by doing so are leaking their clearnet certificates - most of the time this isn't that big a deal because the site is declared on the clearnet and the owner is clear, but there are definitely a few cases where this leak is purely accidental - my favorite is an anonymous hacktivist site which serves the https certificate for someones personal blog.
There are also a few clusters on here with self signed certificates, these are the most interesting as we can often link seemingly unrelated sites by using information that leaks in the self signed certificate - things like emails, hostnames, IP address etc can leak into certificates and can be used to cluster sites - so you can see on here a few distinct clusters that are connected by unique TLS properties.

Now onto a fun story about google analytics IDs, google analytics as you may know is an analytics platform provided by google, and to use it you past some javascript into you site, and that javascript contains a unique ID. Similairy if you are hosting adsense ads on your site you get another piece of javascript with another unique ID.
We have detected a bunch of sites with the analytics and publisher IDs, the largest of which was a bunch of casino sites, some exclusively on the dark web, some with clearnet versions - but all of them with the same anaytics ids - these sites had different names and themes - some from roulette some for poker etc. but we managed to link more than 100 gambling sites, pretty much the entire dark web gambling category to the same analytics id, and thus the same operator.
Revisiting a point from earlier, this means that while it may look like there are 100 gambling sites on the dark web, and this is what a few studies have published, there aren't, there are 100 front sites for the same operation. This is a point I'm going to keep hitting on.
It wasn't just the casino sites, we also found a number of other sites we could link through these identifiers. I even found one example of a drug market which shared an analytics ID with a legitimate clearnet business...Ill let you draw your own conclusions about what that could mean.
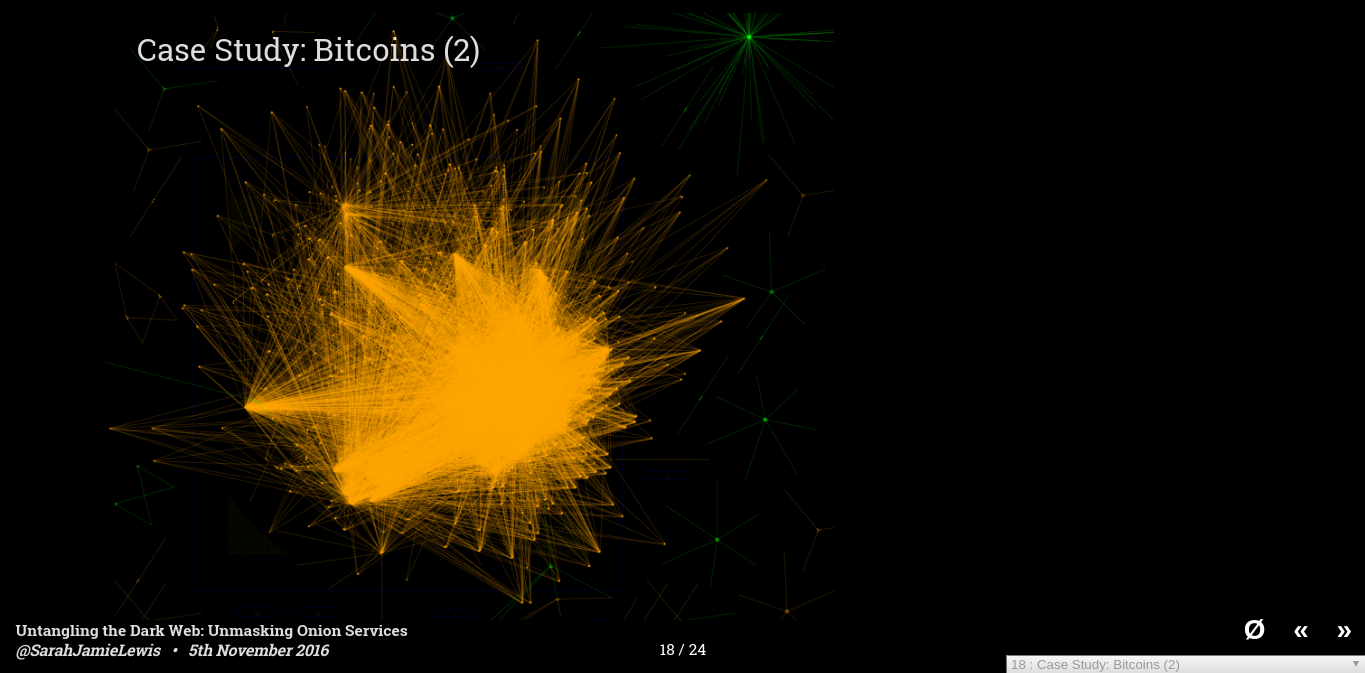
Everyone's favourite cryptocurrency bitcoin is widely used on the dark web. This is actually my first attempt at graphing out sites which shared the same bitcoin address, as you can see it's pretty much a big orange blob - when you actually do a transitive reduction on this graph what you get is a graph covered in orange circles showing that there are many many sites that share bitcoin addresses.
These connections span the rang between obvious clones or duplicate sites, to hidden relationships. One very common thing we saw was small marketplaces that reused bitcoin addresses for payment - which means you could try to by an apple laptop on one site and some cocaine on another site and end up sending bitcoin to the same bitcoin address - it also makes working out how much each dark web site is earning, or how many people are falling for bitcoin scams very easy.

The screenshot above shows two paste bin sites that I found, both French - I actually thought something was broken with the correlation when I first checked this, because while the first site clearly has a bitcoin address on its page, the second one does not. It turns out that the bitcoin address was hidden in the comments - it looks like either one site copied the other and chose to comment out the address instead of remove it - the other option is that this site is run by the same owner who, for whatever reason, chose not to collect bitcoin on the second site.
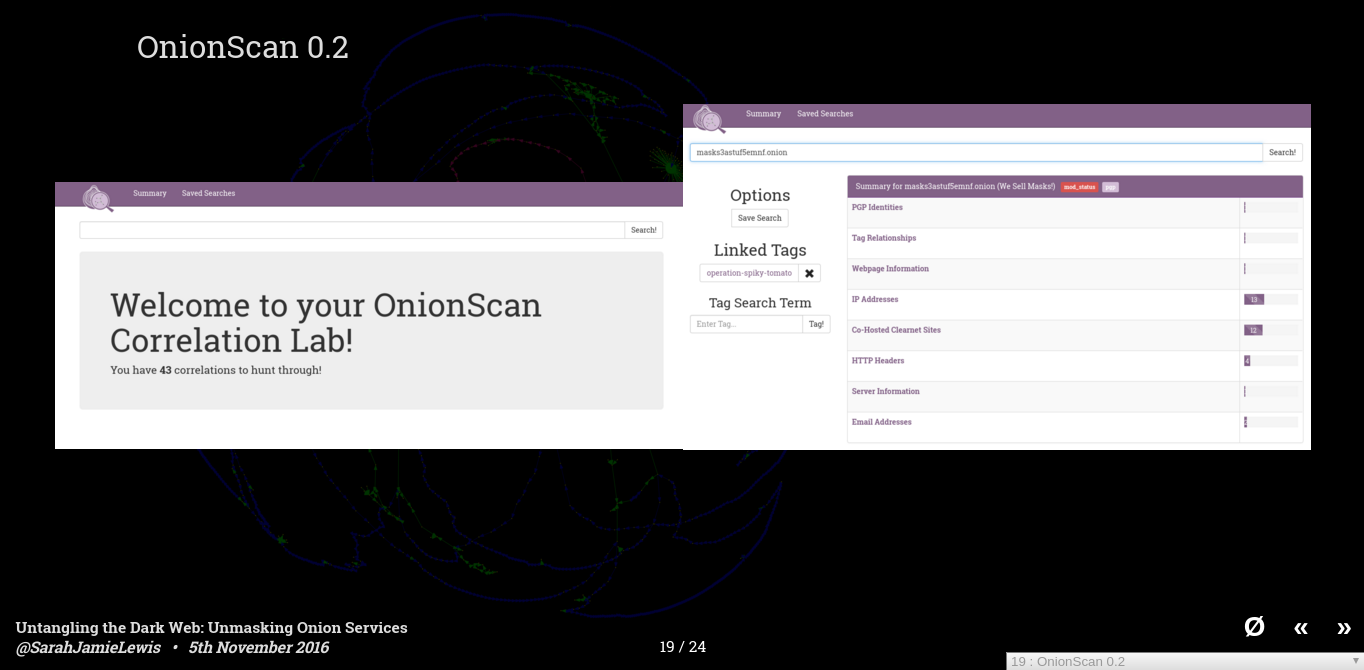
So that was a very quick overview of a number of different correlations that you can do on the dark web - there are many, many more - Last weekend I released OnionScan 0.2 which greatly improves of the April release, and also feature a built in correlation lab - OnionScan now does all of these correlations for you and allows you to shift through hundreds of thousands of correlations quickly and efficiency.
I want to really emphasis that these aren't academic thought exercises, you can download onionscan onto a fresh digital ocean install, run a list of onions that you can pull from any one of clearnet sites and within 1 or 2 days you will be able to deanonymize or other wise find out information about a large portion of the dark web.
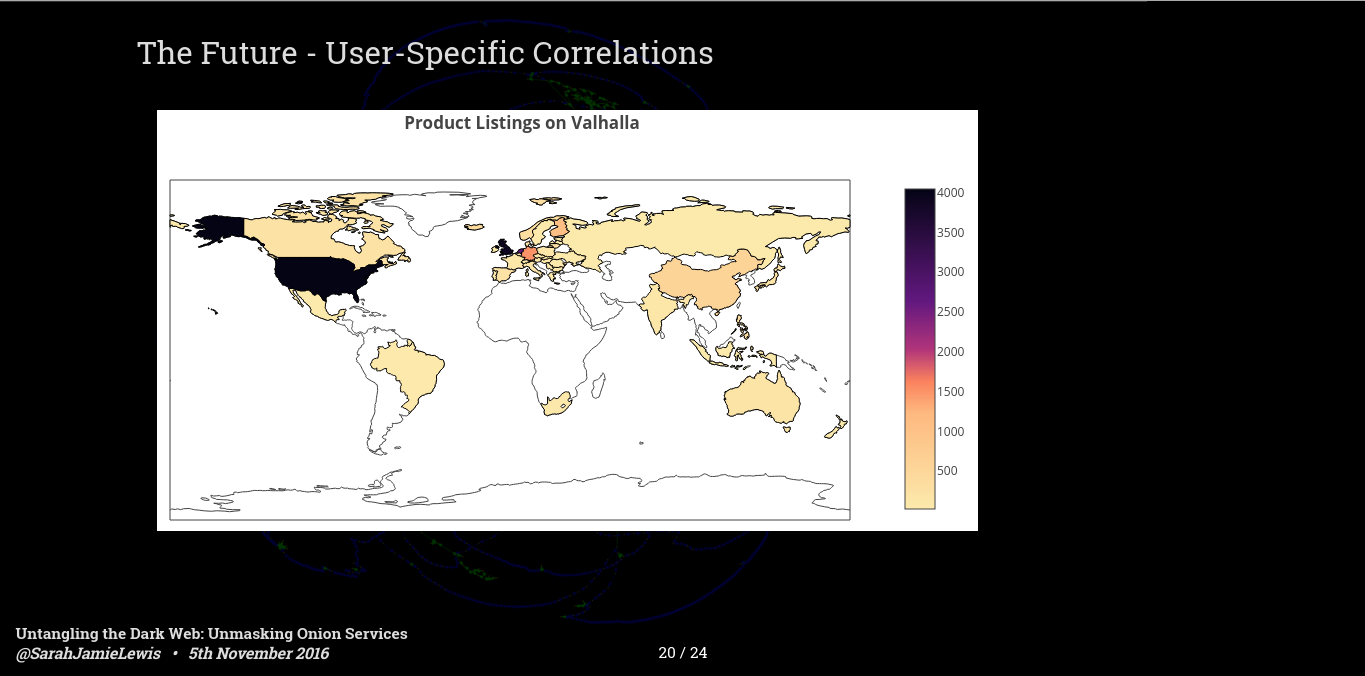
Casting an eye towards the future, I'd like to give you a sneak peek at this months OnionScan report that I will be releasing next week.
The new version of OnionScan doesn't just have preconfigured correlations - it also allowed users to define their own - as part of that I have been running scans against various darknet markets pulling down things like listings, vendors, shipment sources etc. And I am using this data to pull out a lot of information about how these markets are used.
The map above shows countries where vendors claim that they ship from on the Valahalla market. This information is generally given to allow users to make decisions about where they buy from - for example it is generally far riskier to ship inside a country than it is to ship across borders - although some vendors and buyers are willing to do so.
As you can see by this image the darker countries where the most listings originate from are the USA, the UK and though you can't really see it on this map - the Netherlands and Germany are also pretty dark.
The October OnionScan report will be out next week with much more analysis on the vendor makeup of some dark markets, and I will be expanding this research in the coming months.

As I have mentioned throughout the presentation that many of the findings have an big impact on how we think about classifying onion services.
You can find multiple studies, like the one from
DeepLight earlier this year which reported that greater than 50% of Onion Services contained illegal content.
However, such studies never take into account data that I have talked about today - co-hosting analysis, duplication, group analysis - this means that their reports are, to put it frankly, wrong.
You cannot simply count hidden services and report the number. Crime sites are likely heavily over represented in such counts because they are the ones that are worth cloning, and they are likely the ones that have load balanced over multiple domains.
To make this a little better, I have started a project to manually categorize 6000 onion domains, including performing proper duplicate and cloning analysis, and, if I can work out a way to do it properly, grouping analysis. . I am about half way through, and it is slow going - but once it is done, I am hoping it can advance the conversation about the uses of the Dark Web.

Looking further into the future - how can we make the dark web better? Currently the Dark Web is more like geocities than an underground cyberpunk net.
There are technologies that are changing the balance. OnionShare and Ricochet use hidden services to remove metadata from filesharing and instant messaging respectively.
One I am particularly excited about is OpenBazaar a peer to peer marketplace platform - that isn't yet anonymous, but there are plans to make it so.
Peer to peer tech is much less prone to the attacks I have described, because they don't have to content with the large attack surface of general web platforms - and they can be designed with that in mind.
Personally, I think another trend evident in these new technologies is a move away from the browser. As awesome as the effort that has been put into the Tor browser, and indeed any other browser, is - the fact remains that browsers are littered with 0-days - and when you are relying on tech to preserve your life or your freedom, you need tools with a much smaller attack surface than a browser.

This week Quebec has been rocked by news that local and provincial police forces have been spying on journalists, in an attempt to determine their sources.
Such behavior has no place in free and just society - and while it is important to let the judicial process unfold, it is clear that power, in any form will always seek to perpetuate itself.
Using these tools, you take that power away and distribute it among the people - this is by no means a free pass to be unethical - there are very few crimes in a free society that can be undertaken entirely online - the trafficking of guns, humans and child exploitation requires a real world component and it requires trust - this trust can always be broken by a dedicated investigation task force - people are rarely infallible.
But by encouraging the adoption and betterment of these technologies I advocate for the adoption of a freer world, a world where governments can't blanket spy on an entire population, where whistleblowers are able to report unethical practice, where domestic violence victims can escape and where queer people can explore their gender or sexuality without facing judgement or abuse of an oppressive society.
In Summary, Anonymity is hard, our tools suck, our software sucks, people don't know the risks, and right now a large portion of the dark web really isn't that dark.
From simple exploitation to large scale correlations it is often trivial to uncover links and even direct deanonymizations of gun markets, illicit file sharing and also sadly political blogs and journalistic outlets
If this stuff interests you and you would like to read the full reports around these issues you can find them and many others on mascherari.press - If you'd like to get involved in OnionScan,or would my help exploring this space you can also email me@sarahjamielewis.com or follow me on twitter @SarahJamieLewis - I tweet about this stuff on a daily basis.
Thank You for listening.
If you would like to support further research and development of tools like OnionScan you can become a patron at Patreon
