OnionScan 0.2 has been released! This article will take you through one of the newest and most powerful features - custom crawls.
OnionScan 0.2 has been Released! https://t.co/qb4WAGRIiT - Your new Dark Web Correlation Lab awaits! pic.twitter.com/OFTgjNz4EY
— OnionScan (@OnionScan) October 30, 2016
You may already know that OnionScan comes packed with logic for pulling out many different types of identifiers from onion services e.g. bitcoin addresses, pgp keys and email addresses.
However, many services publish data in non-standard formats, making it difficult for any tool to automatically process it.
OnionScan helps solve this problem by providing a way to define custom relationships for each site - these relationships then get imported into it's Correlation Engine letting them be discovered, sorted and correlated like any other identifier.
As an example, let's look at Hansa Market. If we were investigating this market we would like want to know what listings were available, for what categories and who was selling them. It turned out we can get all of this information from the /listing page of a product:
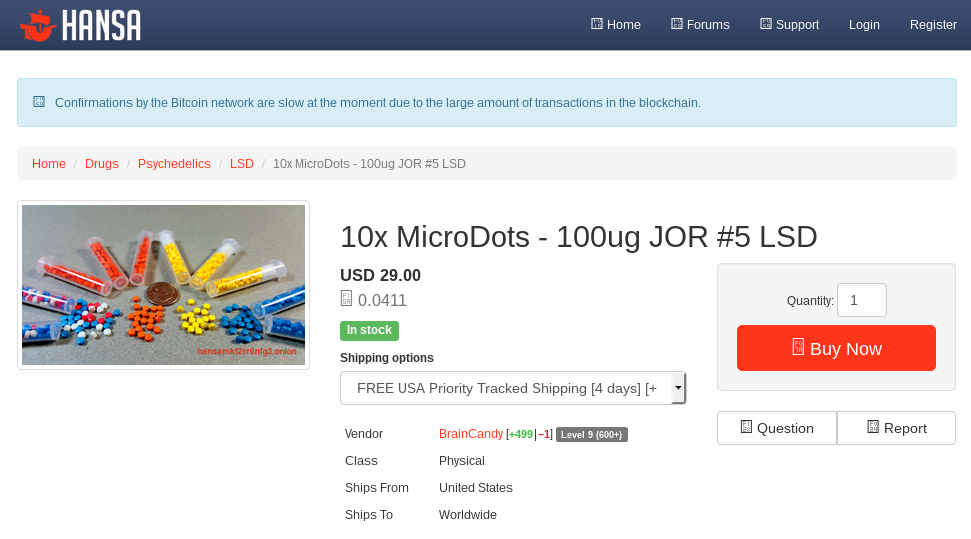
Before, we would have to build a custom web crawler to pull the data down, process it and put it into a form we can analyze. With OnionScan 0.2 we just need to define a small configuration file:
{
"onion":"hansamkt2rr6nfg3.onion",
"base":"/",
"exclude":["/forums","/support", "/login","/register","?showFilters=true","/img", "/inc", "/css", "/link", "/dashboard", "/feedback", "/terms", "/message"],
"relationships":[{"name":"Listing",
"triggeridentifierregex":"/listing/([0-9]*)/",
"extrarelationships":[
{
"name":"Title",
"type":"listing-title",
"regex":"<h2>(.*)</h2>"
},
{
"name":"Vendor",
"type":"username",
"regex":"<a href=\"/vendor/([^/]*)/\">"
},
{
"name":"Price",
"type":"price",
"regex":"<strong>(USD [^<]*)</strong>"
},
{
"name":"Category",
"type":"category",
"regex":"<li><a href=\"/category/[0-9]*/\">([^<]*)</a></li>",
"rollup": true
}
]
}
]
}
That's a lot to take in so we will break it down.
The first two configurations specify the onion service we are targeting ("onion":"hansamkt2rr6nfg3.onion") and the base URL we want to start scanning from ("base":"/"). Some onionservices only have useful data in subdirectories e.g. /listings in that case we could use base to tell OnionScan to ignore all other parts of the site.
The next configuration exclude tells OnionScan to exclude certain links like "/forums","/support", "/login","/register" - these are links which we don't want to click on because they take us offsite, or perform actions we don't want to take.
Finally we have relationships and this is where our custom crawl logic happens.
A relationship is defined by a name and a triggeridentifierregex - the regex is applied to the URL of the site and when it matches the rest of the rules in the relationship are triggered. In this case we tell OnionScan that URLs matched "/listing/([0-9]*)/" will trigger the Listing relationship. OnionScan will also treat the number in the url (([0-9]*)) as a unique identifier for the relationship.
Next each relationship can have extrarelationships - these are relationships that OnionScan will look for and assign to the unique identifier that we have extracted above.
For example, in our configuration file we define 4 extra-relationships Title, Vendor, Price and Category. Each extra-relationship as a name, a type - which OnionScan uses in it's Correlation Engine and a regular expression regex. The regular expression is used to extract the relationship from the page that we have previously triggered.
For the Hansa market example, we can see that from the /listing/ page for a product being sold we can grab the vendors name by looking for a hyperlink with the structure<a href=\"/vendor/([^/]*)/\">. Similarly we can find the title, price and category of the listing by searching for similar structures.
The rollup parameter under Category is an instruction for OnionScan to calculate statistics on the different kinds of Categories we find, and the graph them in the Correlation lab.
At this point we have told OnionScan how to read a marketplace listing from Hansa market, but how does OnionScan use it?
Placing the configuration above in a folder called service-configs we can call OnionScan to scan the market with the following:
./onionscan -scans web --depth 1 --crawlconfigdir ./service-configs/ --webport 8080 --verbose hansamkt2rr6nfg3.onion
After letting OnionScan run for a while, you can navigate to localhost:8080 and enter hansamkt2rr6nfg3.onion in the search.
Scrolling down the list of relationships you should eventually find something that looks like this:
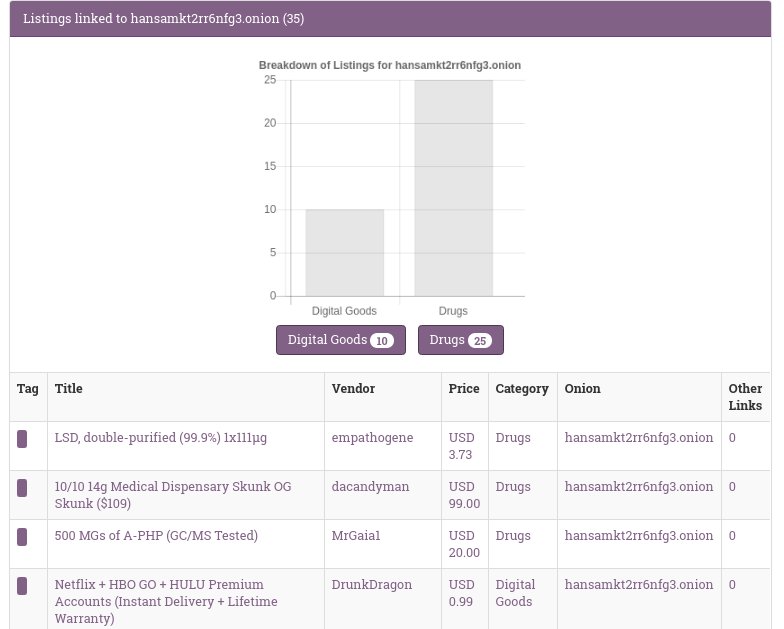
As you can see OnionScan has taken our small config file and transformed it into relationships capable of working with OnionScan's Correlation Engine. Each of the those relationships we defined earlier is now searchable and can correlated against anything else that OnionScan has found - for example - if we were to scan another marketplace of forum where a vendor had reused their name or product title then we can find relationships across onion services!
The graph is generated because we told OnionScan to rollup the Category relationship that we defined earlier.
We hope that you find this feature as powerful as we do, and that users start to maintaining and sharing configurations for all kinds of hidden services.
This is just the start! There are many more features that we want to add to OnionScan - come help us by joining the discussion on Github!
If you would like to support further research and development of tools like OnionScan you can become a patron at Patreon
