Practically every technology company is now using machine learning in their day-to-day operations. The statistical algorithms that were once reserved for academia are now even being picked up by more traditional industries as software continues to eat the world.
However, in all the excitement there has been one element of the problem that is still left behind on the academic shelf, and that, of course, is security.
While machine learning has made it into the security field; being used in the fields of intrusion detection and malware classification, among others - the underlying algorithms have received little attention.
A quick search on using machine learning in your applications will provide plenty of articles documenting best practices, however, few will cover the techniques and design decisions that you will need to adopt to keep your models safe.
This is a collection of resources, articles, tutorials and guidance to help you adopt secure practices for machine learning.
Introduction / General Overview
Adversarial machine learning is a research field that lies at the intersection of machine learning and computer security.
All machine learning algorithms and methods are vulnerable to many kinds of threat models.
The Machine Learning Threat Model
At the highest level, attacks on machine learning systems can be classified into one of two types: Evasion attacks and Poisoning attacks.
Evasion Attacks
The simplest kind of attacks of models are attacks which attempt to bypass the learning outcome.
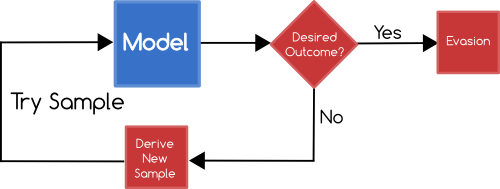
For example, an attacker who wishes to send spam emails could first try a number of different email contents against the model to try and discover a way to get their spam email classified as innocuous.
Relatedly, an attacker may try learning how to trigger positive matches in a given model in an attempt to drive up the rate of false negatives so as to make the model practically unstable.
Poisoning Attacks
An attacker may focus on influencing your training data in an attempt to influence the learning outcome
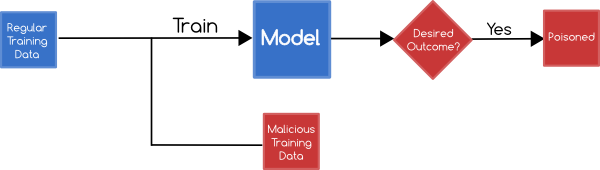
For example, an attacker who knows that network traffic is currently being collected to train a classifier that detects anomalous traffic can then send traffic to that network such that when the model is built it will fail to classify the attacks connections as out of the ordinary.
Various domains are very susceptible to poisoning attacks e.g. Network Intrusion, Spam Filtering and Malware Analysis - however, poisoning can occur in any area where training data isn't thoroughly validated and verified before being incorporated into the model.
Beyond Evasion and Poisoning
Researchers have constructed a taxonomy of potential attacks targeted at statistical systems. Using that taxonomy we can classify attacks using 3 properties:
Whether the attack is Causative, where the attacker is able to influence the training data; or Exploratory, where the attacker is unable to influence the training data and instead can only identify learning outcomes.
Whether the attack focuses on Integrity, where an attacker attempts to learn how the model treats data and to construct samples which violates the goals of the model, Availability where the attacker tries to overwhelm the system with false positives; or Privacy where the attacker tries to gain information from the model itself.
Whether the attack is Targeted, where the attack is focused on manipulating a small set of features or points (e.g. get my spam email through the classifier); or Indiscriminate where the attack has a more flexible goal (e.g. get any spam email through the classifier)
Machine Learning Security Best Practices
Like all security, the solution to adversarial machine learning is layered defenses - and there is no one-stop patch. However, there are a few techniques that can be used to minimize your risk footprint:
1. Understanding Training Data
Being able to identify the sources of the data and evaluating the likelihood of compromise is a good first steps to understanding the level of risk associated with incorporating it into your model.
2. Sanitizing Your Training Data
When it is not possible to check every source - or there is simply a high level of risk evident in the problem domain e.g. network intrusion detection. Then it is necessary to buidt checks into your training method.
A Reject on Negative Impact defense measures the impact of adding each new training sample, and discards samples which have a significantly negative impact on the learning outcomes.
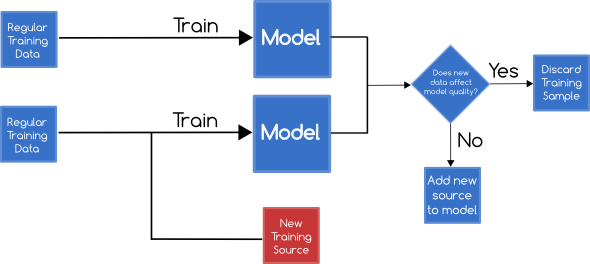
This can be done by training 2 classifiers - one with the base training set, and another with the base training set and the new data sample. Both classifiers are then subjected to a set of tests with known labels to determine their accuracy.
If the 2nd classifier is significantly worse than than the 1st then the new training data can be discarded marked as malicious.
3. Examine Your Algorithms
Certain machine learning algorithms e.g. ANTIDOTE have combined existing algorithms with techniques from the field robust statistics. The hardened algorithms that assume that a small portion of data is likely to be malicious and have built in countermeasures to limit the impact of poisoning.
Wait! What about Evasion Attacks!?
Unfortunately, combating evasion attacks is the same problem that lies at the heart of machine learning - better algorithms will, by definition, be better at thwarting evasion attacks.
The best that you can do is understand that this is a problem inherent to every machine learning approach and focus on building layered defenses such that a failure in one model doesn't mean a security disaster for your application.
Adversarial Machine Learning Literature
If you would like to dive into the academic research - and I encourage you to
do so - I have collected a number of different articles below.
General
- Can Machine Learning Be Secure?
- Adversarial Machine Learning
- Explaining and Harnessing Adversarial Examples
- Adversarial Learning
- Pattern Recognition Systems Under Attack: Design Issues and Research Challenges
- Evasion attacks against machine learning at test time
- A Framework for Quantitative Security Analysis of Machine Learning
- Machine Learning Methods for Computer Security
- Understanding the Risk Factors of Learning in Adversarial Environments
Support Vector Machines
- Security Evaluation of Support Vector Machines in Adversarial Environments
- Poisoning Attacks against Support Vector Machines
- Support Vector Machines Under Adversarial Label Noise
- Adversarial Label Flips Attack on Support Vector Machines
Neural Networks / Deep Learning
- Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images.
- The Limitations of Deep Learning in Adversarial Settings
- How to trick a neural network into thinking a panda is a vulture
Online Learning
- Online Learning with Adversarial Delays
- Online Learning under Delayed Feedback
- Online Anomaly Detection under Adversarial Impact
Classification
- Adversarial Classification
- Multiple Classifier Systems Under Attack
- Multiple Classifier Systems for Robust Classifier Design in Adversarial Environments
- Adversarial Pattern Classification Using Multiple Classifiers and Randomisation
- Bagging Classifiers for Fighting Poisoning Attacks in Adversarial Classification Tasks
- Security evaluation of pattern classifiers under attack
Clustering
Application Specific Resources
There are many domains in which knowledge of adversarial machine learning isn't just useful - it is necessary. Below are a collection of domain-specific papers, categorized by area.
Intrusion Detection
- Adversarial Attacks against Intrusion Detection Systems: Taxonomy, Solutions and Open Issues
- Attacks Against Intrusion Detection Networks: Evasion, Reverse Engineering and Optimal Countermeasures
Spam Filtering
Biometrics
A note on completeness and future work.
Adversarial Machine Learning, much like machine learning in general, is a very new field and new papers are written and published all the time.
As work becomes available I will endeavor to keep this page up to date.
If you know of a paper related to #amlsec which isn't listed above please get in touch - I would love to add it to the collection (and read it myself!)
